

In today’s data-driven world, organizations harness data’s power to drive innovation, inform decisions, and fuel growth. But behind every successful data strategy lies a crucial component: data engineering. The unsung hero of data science, data engineering is the backbone that transforms raw data into actionable insights. In this article, we’ll delve into the world of data engineering, exploring its importance, role, and impact on data science. From data pipelines to architecture, discover how data engineering is revolutionizing how we extract value from data. Let’s dive in! Fundamentals Of Data Engineering
"Data Types and Sources: The Diverse World of Data"

Imagine you’re a chef, and data is your ingredient. Just as a recipe requires different ingredients, data analysis requires different data types. Let’s explore the diverse world of data types and sources, and how they impact data engineering. Fundamentals Of Data Engineering
Structured Data: The Organized Kitchen
Structured data is like a perfectly organized kitchen, where every ingredient has its place. It’s highly organized, easily searchable, and follows a specific format. Examples include:
- Customer information (name, address, phone number)
- Financial transactions (date, amount, category)
- Sensor data (temperature, humidity, pressure)
Think of a relational database like a recipe book, where each entry follows a specific format, making it easy to access and analyze. Fundamentals Of Data Engineering
Semi-Structured Data: The Flexible Recipe
Semi-structured data is like a recipe with some flexibility. It has some organization but is not as rigid as structured data. Examples include:
- XML documents (data wrapped in tags)
- JSON files (data in key-value pairs)
- CSV files (data separated by commas)
Semi-structured data is like a recipe with room for creativity. It’s easy to add or remove ingredients without disrupting the entire dish. Fundamentals Of Data Engineering
Unstructured Data: The Kitchen Sink
Unstructured data is like a kitchen sink full of random ingredients. It lacks organization and format, making it challenging to analyze. Examples include:
- Images (photos, videos)
- Audio files (music, podcasts)
- Text documents (emails, social media posts)
Unstructured data is like a mystery box of ingredients. It requires creative thinking and specialized tools to extract valuable insights. Fundamentals Of Data Engineering
"Data Storage: Where Your Data Calls Home"

Think of data storage as a home for your data. Just as you need a comfortable and secure place to live, your data needs a suitable storage solution to rest and thrive. Let’s explore the various data storage options, each with its unique characteristics, advantages, and use cases. Fundamentals Of Data Engineering
Relational Databases: The Traditional Home
Relational databases are like a cozy, traditional home, where everything has its place. They use tables, rows, and columns to store data, making it easily searchable and accessible. Examples include:
- MySQL (popular for web applications)
- PostgreSQL (known for its reliability)
- Oracle (widely used in enterprises)
Imagine a library, where books (data) are organized on shelves (tables), and each book has a unique title (primary key). Relational databases are perfect for structured data and support complex queries. Fundamentals Of Data Engineering
NoSQL Databases: The Flexible Loft
NoSQL databases are like a trendy, flexible loft, where you can arrange your furniture (data) as you like. They store data in documents, key-value pairs, or graphs, making them ideal for semi-structured and unstructured data. Examples include:
- MongoDB (popular for document-based data)
- Cassandra (known for its scalability)
- Redis (widely used for caching and messaging)
Picture a hipster café, where each table (document) has a unique vibe (schema-less data). NoSQL databases are perfect for flexible, modern applications and big data. Fundamentals Of Data Engineering
Data Warehousing: The Data Mansion
Data warehousing is like a grand mansion, where all your data comes together for analysis and insights. It’s a centralized repository that stores data from various sources, making it easily accessible for reporting and visualization. Examples include:
- Amazon Redshift (cloud-based data warehousing)
- Google BigQuery (serverless data warehousing)
- Apache Hive (open-source data warehousing)
Imagine a luxurious mansion, where all your data (from various rooms) is gathered in a grand hall (data warehouse) for a lavish party (analysis and insights). Data warehousing is perfect for business intelligence and data analytics. Fundamentals Of Data Engineering
"Data Processing: The Power Behind the Insights"
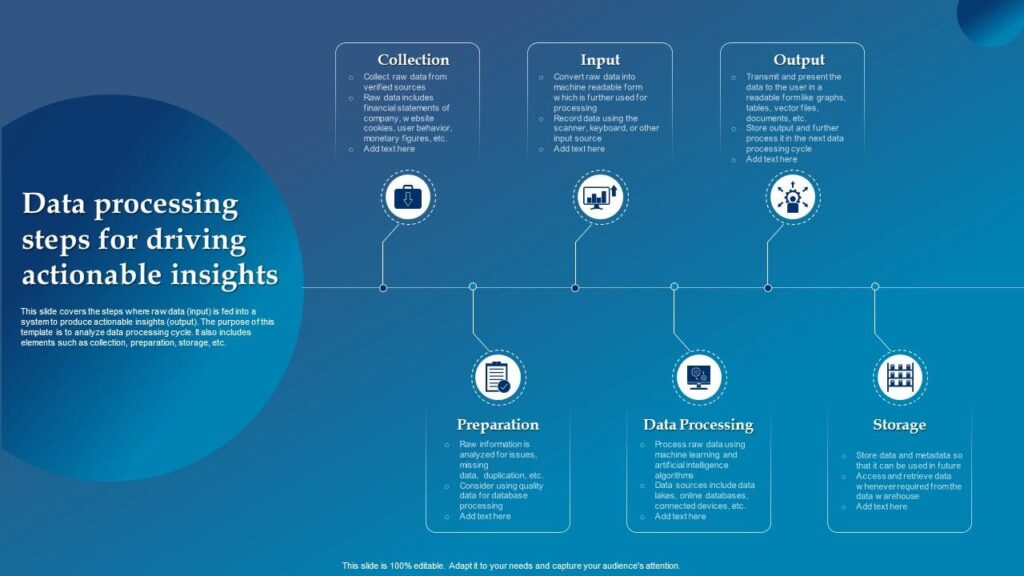
Think of data processing like a master chef, who takes raw ingredients (data) and turns them into a culinary masterpiece (insights). Just as a chef uses various cooking techniques, data processing uses different methods to transform data into actionable information. Let’s explore the three main data processing concepts, each with its unique flavor and purpose. Fundamentals Of Data Engineering
Batch Processing: The Slow-Cooked Stew
Batch processing is like cooking a hearty stew, where all the ingredients are combined and cooked in batches. It’s a traditional approach, where data is collected, processed, and analyzed in batches, often on a schedule. Examples include:
- Payroll processing (monthly)
- Billing and invoicing (quarterly)
- Data backups (daily)
Imagine a cozy Sunday afternoon, where you cook a big batch of stew, letting it simmer for hours. Batch processing is perfect for non-time-sensitive tasks, where data can be processed in bulk. Fundamentals Of Data Engineering
Stream Processing: The Sizzling BBQ
Stream processing is like a sizzling BBQ, where data is processed in real-time, as it’s generated. It’s a fast-paced approach, where data is analyzed and acted upon immediately. Examples include:
- Fraud detection (in real-time)
- Social media monitoring (live)
- IoT sensor data analysis (continuous)
Picture a summer BBQ, where burgers are cooked and served immediately. Stream processing is perfect for time-sensitive tasks, where data needs to be processed and acted upon quickly. Fundamentals Of Data Engineering
Real-Time Processing: The Instant Noodle
Real-time processing is like cooking instant noodles, where data is processed and analyzed in a split second. It’s an ultra-fast approach, where data is processed as soon as it’s generated. Examples include:
- High-frequency trading (nanoseconds)
- Autonomous vehicles (milliseconds)
- Real-time analytics (seconds)
Imagine a busy morning, where you quickly cook instant noodles for a fast breakfast. Real-time processing is perfect for applications that require lightning-fast insights and decisions. Fundamentals Of Data Engineering
"Data Architecture: The Blueprint for Success"
Think of data architecture like building a dream home, where a sturdy foundation and clever design are crucial. Just as a well-designed house makes life easier and more enjoyable, a well-planned data architecture makes data management and analysis a breeze. Let’s explore three popular data architecture patterns, each with its unique characteristics and advantages. Fundamentals Of Data Engineering
Monolithic Architecture: The Classic Mansion
Monolithic architecture is like a grand, classic mansion, where everything is built together in a single, self-contained unit. It’s a traditional approach, where data is stored, processed, and analyzed in a single database or system. Examples include:
- Legacy systems (older software applications)
- Simple e-commerce platforms (small online stores)
- Personal productivity tools (note-taking apps)
Imagine a beautiful, sprawling mansion, where everything is connected and works together seamlessly. Monolithic architecture is perfect for small to medium-sized applications with simple data needs. Fundamentals Of Data Engineering
Microservices Architecture: The Modern Compound
Microservices architecture is like a modern compound, where multiple smaller buildings (services) work together to form a cohesive whole. Each service is independent, scalable, and communicates with others through APIs. Examples include:
- Large e-commerce platforms (Amazon, eBay)
- Social media platforms (Facebook, Twitter)
- Complex enterprise applications (banking, healthcare)
Picture a sleek, modern compound, where each building has its purpose, but they all work together in harmony. Microservices architecture is perfect for large, complex applications with diverse data needs. Fundamentals Of Data Engineering
Event-Driven Architecture: The Dynamic City
Event-driven architecture is like a dynamic city, where events (data changes) trigger actions and reactions across the system. It’s a flexible approach, where data is processed and analyzed in real-time, as events occur. Examples include:
- Real-time analytics platforms (Google Analytics)
- IoT sensor networks (smart homes, industrial sensors)
- High-frequency trading systems (financial markets)
Imagine a bustling city, where events happen constantly, and the infrastructure responds and adapts in real time. Event-driven architecture is perfect for applications that require rapid data processing and insights. Fundamentals Of Data Engineering
"Data Quality, Governance, and Security: The Guardians of Trust"

Think of data quality, governance, and security like a team of guardians, protecting your data from errors, misuse, and threats. Just as a good guardian ensures the well-being and safety of their charge, these three aspects work together to ensure your data is accurate, reliable, and secure. Fundamentals Of Data Engineering
Data Quality: The Accuracy Advocate
Data quality is like a meticulous editor, ensuring every detail is correct and consistent. It’s about ensuring data is accurate, complete, and reliable, so you can trust the insights you gain from it. Examples include:
- Data validation rules (checking for errors)
- Data cleansing (removing duplicates or incorrect data)
- Data normalization (standardizing formats)
Imagine a journalist fact-checking an article, ensuring every detail is accurate before publication. Data quality is essential for reliable analytics and decision-making. Fundamentals Of Data Engineering
Data Governance: The Policy Protector
Data governance is like a wise policymaker, setting rules and guidelines for data management and use. It’s about defining roles, responsibilities, and procedures for data handling, ensuring everyone knows what’s expected of them. Examples include:
- Data access controls (who can see what data)
- Data retention policies (how long data is kept)
- Data privacy regulations (compliance with laws like GDPR)
Picture a librarian, carefully cataloging and managing books, ensuring they’re accessible and protected. Data governance ensures data is managed and used responsibly. Fundamentals Of Data Engineering
Data Security: The Threat Protector
Data security is like a vigilant bodyguard, protecting data from unauthorized access, theft, or damage. It’s about implementing measures to prevent data breaches and cyber-attacks. Examples include:
- Encryption (scrambling data to prevent unauthorized access)
- Access controls (limiting who can see or modify data)
- Incident response plans (responding quickly to security breaches)
Imagine a security guard, watching over a valuable treasure, ready to respond to any threats. Data security is crucial for protecting sensitive information. Fundamentals Of Data Engineering
"Data Engineering Toolbox: The Power to Shape Data"
Think of data engineering tools and technologies like a skilled carpenter’s toolbox, where each tool serves a specific purpose in shaping and crafting data. Just as a carpenter needs a reliable toolbox to build a sturdy house, data engineers rely on a variety of tools to manage and analyze data. Let’s explore some popular data engineering tools and technologies, each with its unique strengths and use cases. Fundamentals Of Data Engineering
Apache Hadoop: The Reliable Workhorse
Apache Hadoop is like a trusty pickup truck, dependable and hardworking. This open-source framework is designed for storing and processing large datasets, making it a popular choice for big data processing. Examples include:
- Data warehousing (storing large amounts of data)
- Data processing (distributing tasks across multiple nodes)
- Data analytics (generating insights from large datasets)
Imagine a farmer using a reliable pickup truck to haul heavy loads across the farm. Apache Hadoop is a workhorse for data engineering, handling large datasets with ease. Fundamentals Of Data Engineering
Apache Spark: The Speedster
Apache Spark is like a high-performance sports car, built for speed and agility. This open-source engine is designed for real-time data processing, making it a popular choice for fast data analytics. Examples include:
- Real-time analytics (processing data as it’s generated)
- Machine learning (training models on large datasets)
- Data streaming (processing data in real-time)
Picture a racing driver, speeding around the track in a high-performance car. Apache Spark is built for speed, accelerating data processing and analytics. Fundamentals Of Data Engineering
Cloud-Based Services: The Flexible Helper
Cloud-based services are like a versatile multitool, adaptable and convenient. These services provide on-demand access to data engineering tools and technologies, making it easy to scale and manage data infrastructure. Examples include:
- Amazon Web Services (AWS)
- Microsoft Azure
- Google Cloud Platform (GCP)
Imagine a handyman, using a multitool to tackle various tasks around the house. Cloud-based services offer flexibility and convenience for data engineering, providing access to a range of tools and technologies. Fundamentals Of Data Engineering
Pingback: Microsoft Azure Data Engineering Associate (DP-203) - aitechverge.com